Diffusion models have achieved remarkable advancements in text-to-image generation. However, existing models still have many difficulties when faced with multiple-object compositional generation. In this paper, we propose RealCompo, a new training-free and transferred-friendly text-to-image generation framework, which aims to leverage the respective advantages of text-to-image models and spatial-aware image diffusion models (e.g., layout, keypoints and segmentation maps) to enhance both realism and compositionality of the generated images. An intuitive and novel balancer is proposed to dynamically balance the strengths of the two models in denoising process, allowing plug-and-play use of any model without extra training. Extensive experiments show that our RealCompo consistently outperforms state-of-the-art text-to-image models and spatial-aware image diffusion models in multiple-object compositional generation while keeping satisfactory realism and compositionality of the generated images. Notably, our RealCompo can be seamlessly extended with a wide range of spatial-aware image diffusion models and stylized diffusion models.
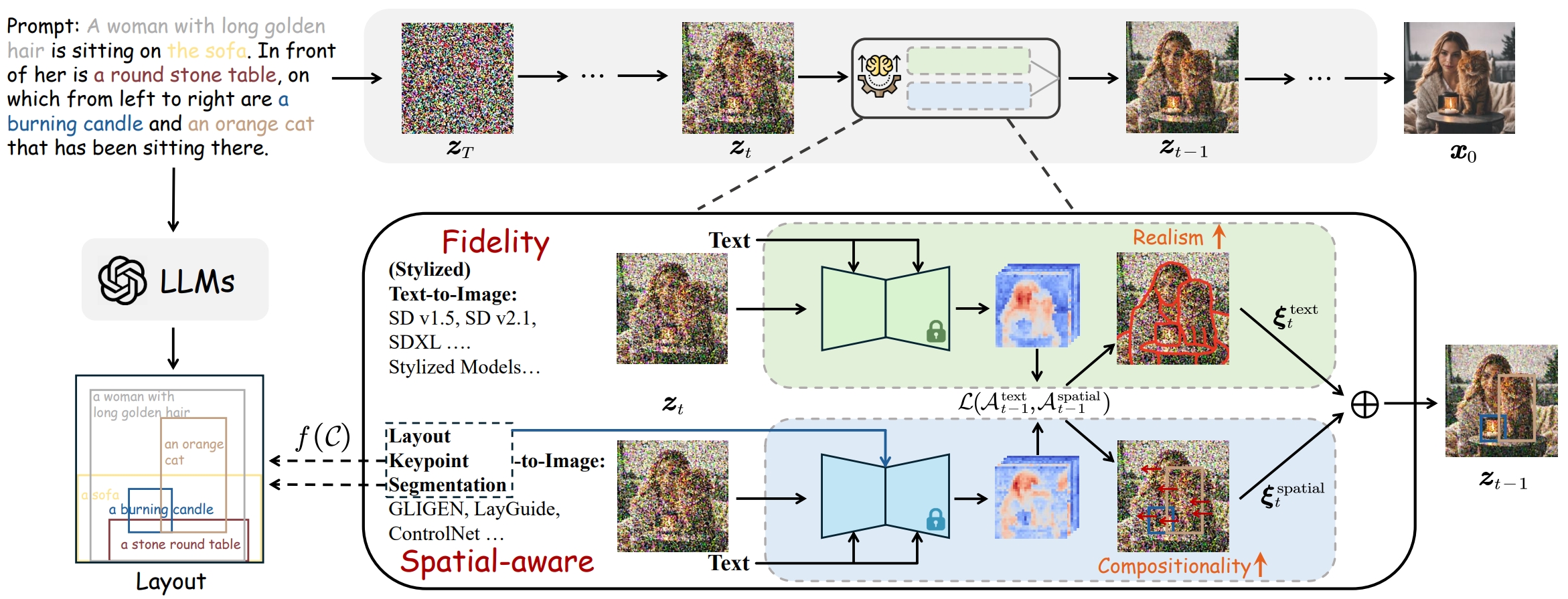
An overview of RealCompo framework for text-to-image generation. We first use LLMs or transfer function to obtain the corresponding layout. Next, the balancer dynamically updates the influence of two models, which enhances realism by focusing on contours and colors in the fidelity branch, and improves compositionality by manipulating object positions in the spatial-aware branch.

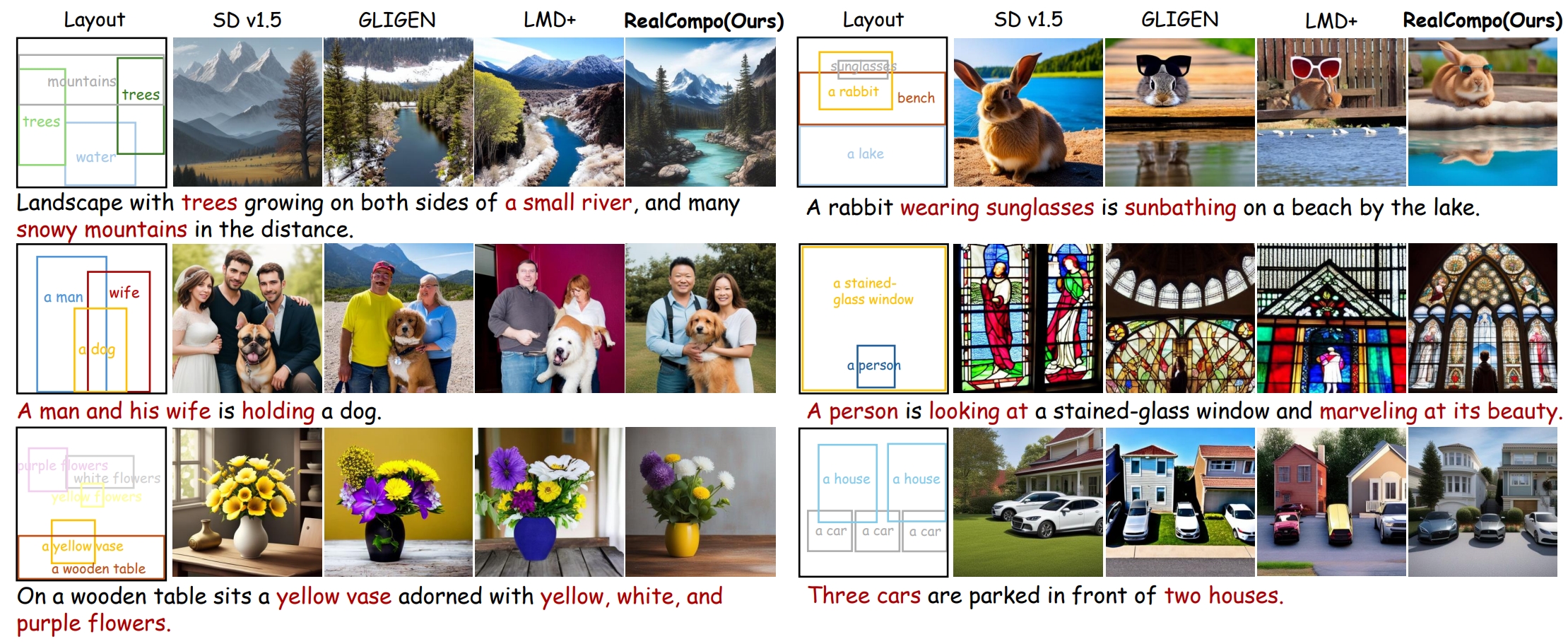
RealCompo achieves satisfactory results in both realism and compositionality in generating images.

Extend Realcompo to keypoint-based image generation.

Extend Realcompo to segmentation-based image generation.
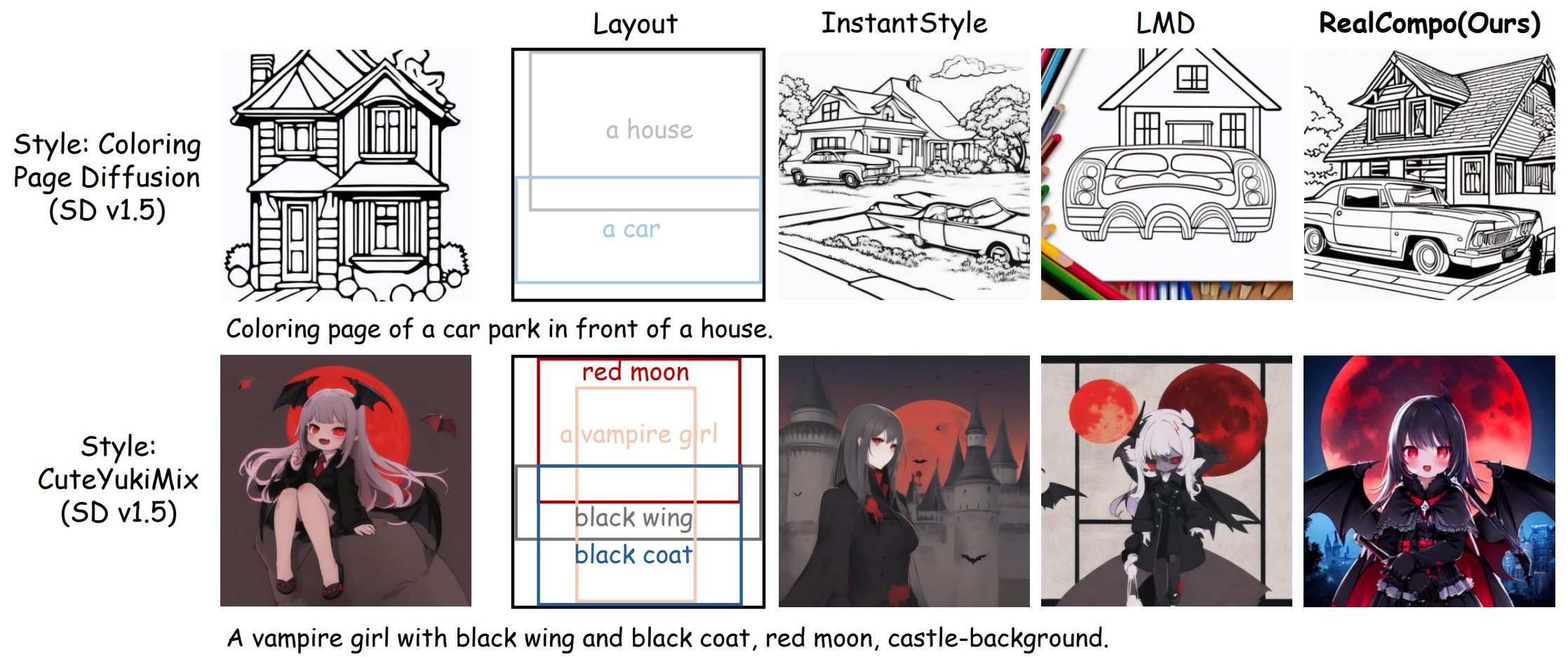
Extend Realcompo to stylized compositional generation.

Qualitative comparison of RealCompo's generalization to different models: We select two T2I models: Stable Diffusion v1.5, TokenCompose, two L2I models GLIGEN, Layout Guidance (LayGuide), and combine them in pairs to obtain four versions of RealCompo. We demonstrate that RealCompo has strong generalization and generality to different models, achieving a remarkable level of both fidelity and precision in aligning with text prompts.
@article{zhang2024realcompo,
author = {Zhang, Xinchen and Yang, Ling and Cai, Yaqi and Yu, Zhaochen and Wang, Kaini and Xie, Jiake and Tian, Ye and Xu, Minkai and Tang, Yong and Yang, Yujiu and Cui, Bin},
title = {RealCompo: Balancing Realism and Compositionality Improves Text-to-Image Diffusion Models},
journal = {arXiv preprint arXiv:2402.12908},
year = {2024},
}